The Decorator pattern is a more flexible alternative to subclassing. The Decorator class implements the same interface as the target and uses aggregation to “decorate” calls to thetarget. Using the Decorator pattern it is possible to change the behavior of the class during runtime.
装饰者模式(decorator)有时又被称为包装者模式(Wrapper)。该模式可以动态的、透明的给对象赋予某些额外的功能。
我们常用的BufferedInputStream就是InputStream的一个装饰者,或者称之为包装类(Wrapper),通过这样我们可以给我们的输入流提供了额外的缓存的功能。
装饰者Decorator和目标的类Target实现同一个接口,使用装饰者模式可以在运行时改变类的行为。
装饰者模式的意图
Attach additional responsibilities to an object dynamically. Decorators provide a flexible alternative to subclassing for extending functionality.
上面这句话的意思是说装饰者模式的意图是给一个对象动态的添加一些功能。相较于子类化来说,装饰者模式更加的灵活可变。
装饰者模式适用的场景
- 用于给对象动态的、透明的添加某些功能。同时又不会影响到其他的对象。
- 当使用继承扩展一个对象是不合适的时候(继承最好是”IS-A”)的关系。
- 有的类是不能继承的,但是你又希望在使用的时候增强它的功能。
具体实例
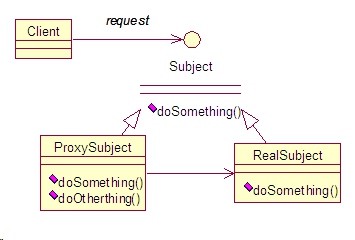
这个装饰者模式的例子共有4个关键的类。Troll巨魔接口, SimpleTroll 普通巨魔, TrollDecorator 巨魔装饰者以及 ClubbedTroll 棍棒巨魔。类之间的继承关系如图所示: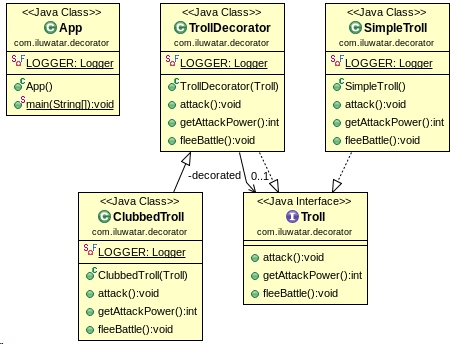
从图中可以看到,SimpleTroll和装饰者TrollDecorator都实现了 Troll 接口。TrollDecorator 包含了一个 Troll 的引用,并对其中的方法使用该引用进行执行。ClubbedTroll 继承了 TrollDecorator ,它也是个装饰器,并对其中的一些方法进行了增强。具体代码如下:Troll 接口:1
2
3
4
5
6
7
8
9public interface Troll {
void attack();
int getAttackPower();
void fleeBattle();
}
装饰者TrollDecorator:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
* TrollDecorator是一个装饰者,持有了一个被装饰者的引用
* 它会拦截对被装饰者的调用,并将调用委托为被装饰者执行
*/
public class TrollDecorator implements Troll {
private Troll decorated;
public TrollDecorator(Troll decorated) {
this.decorated = decorated;
}
public void attack() {
decorated.attack();
}
public int getAttackPower() {
return decorated.getAttackPower();
}
public void fleeBattle() {
decorated.fleeBattle();
}
}
目标类也就是被装饰者SimpleTroll:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
*目标类也就是被装饰者SimpleTroll
*/
public class SimpleTroll implements Troll {
private static final Logger LOGGER = LoggerFactory.getLogger(SimpleTroll.class);
public void attack() {
LOGGER.info("The troll tries to grab you!");
}
public int getAttackPower() {
return 10;
}
public void fleeBattle() {
LOGGER.info("The troll shrieks in horror and runs away!");
}
}
1 | /** |
测试类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class App {
private static final Logger LOGGER = LoggerFactory.getLogger(App.class);
public static void main(String[] args) {
// simple troll
LOGGER.info("A simple looking troll approaches.");
Troll troll = new SimpleTroll();
troll.attack();
troll.fleeBattle();
LOGGER.info("Simple troll power {}.\n", troll.getAttackPower());
// change the behavior of the simple troll by adding a decorator
LOGGER.info("A troll with huge club surprises you.");
Troll clubbed = new ClubbedTroll(troll);
clubbed.attack();
clubbed.fleeBattle();
LOGGER.info("Clubbed troll power {}.\n", clubbed.getAttackPower());
}
}
运行结果:1
2
3
4
5
6
7
8
9
1011:03:44.314 [main] INFO com.iluwatar.decorator.App - A simple looking troll approaches.
11:03:44.317 [main] INFO com.iluwatar.decorator.SimpleTroll - The troll tries to grab you!
11:03:44.317 [main] INFO com.iluwatar.decorator.SimpleTroll - The troll shrieks in horror and runs away!
11:03:44.317 [main] INFO com.iluwatar.decorator.App - Simple troll power 10.
11:03:44.319 [main] INFO com.iluwatar.decorator.App - A troll with huge club surprises you.
11:03:44.320 [main] INFO com.iluwatar.decorator.SimpleTroll - The troll tries to grab you!
11:03:44.320 [main] INFO com.iluwatar.decorator.ClubbedTroll - The troll swings at you with a club!
11:03:44.320 [main] INFO com.iluwatar.decorator.SimpleTroll - The troll shrieks in horror and runs away!
11:03:44.320 [main] INFO com.iluwatar.decorator.App - Clubbed troll power 20.
总结
装饰者模式可以透明的给一个对象增加功能,并不改变对象的使用方法,在现实中使用的也是比较多的。如我们经常用的 BufferedInputStream 就是一个装饰者,它给 InputStream 类增加了缓存的功能。1
2InputStream is = new FileInputStream("path");
BufferedInputStream bis = new BufferedInputStream(is);