Linux中的I/O重定向
I/O 重定向。”I/O”代表输入/输出, 通过这个工具,你可以重定向命令的输入输出,命令的输入来自文件或者标准输入,而输出也存到文件或者直接在Console中打印。 也可以把多个命令连接起来组成一个强大的命令管道。主要包含如下命令。
| 命令 | 含义 |
|---|---|
| cat | 连接文件。 |
| sort | 排序文本行。 |
| uniq | 忽略或者显示重复行 |
| grep | 打印匹配行 |
| wc | 打印文件中的换行符 ,字和字节数 |
| head | 输出文件前10行 |
| tail | 输出文件后10行 |
| tee | 从标准输入读取数据,并写入到标准输出和文件中 |
标准输入,输出,和错误
到目前为止,我们用到的许多程序都会产生某种输出。这种输出,经常由两种类型组成。 第一,程序运行结果;这是说,程序要完成的功能。第二,我们得到状态和错误信息, 这些告诉我们程序进展。如果我们观察一个命令,像 ls,会看到它的运行结果和错误信息 显示在屏幕上。
与 Unix 主题“任何东西都是一个文件”保持一致,程序,比方说 ls,实际上把他们的运行结果 输送到一个叫做标准输出的特殊文件(经常用 stdout 表示),而它们的状态信息则送到另一个 叫做标准错误的文件(stderr)。默认情况下,标准输出和标准错误都连接到屏幕,而不是 保存到磁盘文件。除此之外,许多程序从一个叫做标准输入(stdin)的设备得到输入,默认情况下, 标准输入连接到键盘。
I/O 重定向允许我们可以更改输出走向和输入来向。一般地,输出送到屏幕,输入来自键盘, 但是通过 I/O 重定向,我们可以改变输入输出方向。
重定向标准输出
I/O 重定向允许我们来重定义标准输出送到哪里。重定向标准输出到另一个文件除了屏幕,我们使用 “>” 重定向符,其后跟着文件名。为什么我们要这样做呢?因为有时候把一个命令的运行结果存储到 一个文件很有用处。例如,我们可以告诉 shell 把 ls 命令的运行结果输送到文件 ls-output.txt 中去, 由文件代替屏幕。
使用命令1
yangrubing@eminem:~$ ls ./ > /tmp/ls-output.txt
这样我们就把ls的结果,重定向到ls-output.txt中。查看该文件可以看到: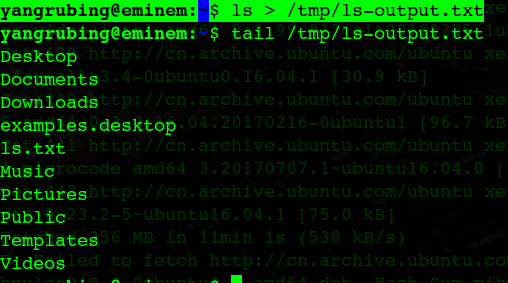
如果我们要追加重定向的信息,而不是覆盖重定向的信息,则可以使用>> 来替代>。1
yangrubing@eminem:~$ ls ./ >> /tmp/ls-output.txt
重定向标准错误
重定向标准错误缺乏专用的重定向操作符。重定向标准错误,我们必须参考它的文件描述符。 一个程序可以在几个编号的文件流中的任一个上产生输出。然而我们必须把这些文件流的前三个看作标准输入,输出和错误,shell 内部参考它们为文件描述符0,1和2,各自地。shell 提供 了一种表示法来重定向文件,使用文件描述符。因为标准错误和文件描述符2一样,我们用这种表示法来重定向标准错误:1
yangrubing@eminem:~$ ls /hello/world > /tmp/ls-output.txt 2>&1
使用这种方法,我们完成两个重定向。首先重定向标准输出到文件 ls-output.txt,然后 重定向文件描述符2(标准错误)到文件描述符1(标准输出)使用表示法2>&1。
也可以使用一个表示法 &> 来重定向标准输出和错误到文件 ls-output.txt1
yangrubing@eminem:~$ ls /hello/world 2>> /tmp/ls-output.txt
重定向标准输入
cat - 连接文件
cat 命令读取一个或多个文件,然后复制它们到标准输出,就像这样:1
cat [file]
在大多数情况下,你可以认为 cat 命令相似于 DOS 中的 TYPE 命令。你可以使用 cat 来显示 文件而没有分页,例如:1
cat ls-output.txt
如果直接输入cat,不加任何参数,它将会等待从键盘中获取输入。我们可以将输入重定向到文件,使用<来完成。1
cat < /tmp/ls-output.txt
管道线(pipeline)
命令可以从标准输入读取数据,然后再把数据输送到标准输出,命令的这种能力被 一个 shell 特性所利用,这个特性叫做管道线。使用管道操作符”|”(竖杠),一个命令的 标准输出可以管道到另一个命令的标准输入:1
command1| command2
command1的输出将作为command2的输入。例如:1
ls -l /usr/bin | less
将ls的结果作为less命令的输入。
过滤器
管道线经常用来对数据完成复杂的操作。有可能会把几个命令放在一起组成一个管道线。 通常,以这种方式使用的命令被称为过滤器。过滤器接受输入,以某种方式改变它,然后 输出它。第一个我们想试验的过滤器是 sort。想象一下,我们想把目录/bin 和/usr/bin 中 的可执行程序都联合在一起,再把它们排序,然后浏览执行结果:1
ls /bin /usr/bin | sort | less
uniq查找或忽略重复行
uniq 命令经常和 sort 命令结合在一起使用。uniq 从标准输入或单个文件名参数接受数据有序 列表(详情查看 uniq 手册页),默认情况下,从数据列表中删除任何重复行。所以,为了确信 我们的列表中不包含重复句子(这是说,出现在目录/bin 和/usr/bin 中重名的程序),我们添加 uniq 到我们的管道线中:1
ls /bin /usr/bin | sort | uniq | less
在这个例子中,我们使用 uniq 从 sort 命令的输出结果中,来删除任何重复行。如果我们想看到 重复的数据列表,让 uniq 命令带上”-d”选项,就像这样:1
ls /bin /usr/bin | sort | uniq -d | less
wc 打印行,字和字节数
wc(字计数)命令是用来显示文件所包含的行,字和字节数。例如:1
2wc ls-output.txt
7902 64566 503634 ls-output.txt
在这个例子中,wc 打印出来三个数字:包含在文件 ls-output.txt 中的行数,单词数和字节数, 正如我们先前的命令,如果 wc 不带命令行参数,它接受标准输入。”-l”选项限制命令输出只能 报道行数。添加 wc 到管道线来统计数据,是个很便利的方法。查看我们的有序列表中程序个数, 我们可以这样做:1
2ls /bin /usr/bin | sort | uniq | wc -l
2728
grep - 打印匹配行
grep 是个很强大的程序,用来找到文件中的匹配文本。这样使用 grep 命令:1
grep pattern [file...]
当 grep 遇到一个文件中的匹配”模式”,它会打印出包含这个类型的行。grep 能够匹配的模式可以 很复杂,但是现在我们把注意力集中在简单文本匹配上面。在后面的章节中,我们将会研究 高级模式,叫做正则表达式。
比如说,我们想在我们的程序列表中,找到文件名中包含单词”zip”的所有文件。这样一个搜索,可能让我们了解系统中的一些程序与文件压缩有关系。这样做:1
2
3
4
5ls /bin /usr/bin | sort | uniq | grep zip
bunzip2
bzip2
gunzip
...
grep 有一些方便的选项:”-i”使得 grep 在执行搜索时忽略大小写(通常,搜索是大小写 敏感的),”-v”选项会告诉 grep 只打印不匹配的行。
head / tail - 打印文件开头部分/结尾部分
有时候你不需要一个命令的所有输出。可能你只想要前几行或者后几行的输出内容。 head 命令打印文件的前十行,而 tail 命令打印文件的后十行。默认情况下,两个命令 都打印十行文本,但是可以通过”-n”选项来调整命令打印的行数。1
2
3
4
5head -n 5 ls-output.txt
total 343496
...
tail -n 5 ls-output.txt
...
它们也能用在管道线中:1
2
3ls /usr/bin | tail -n 5
znew
...
tail -f 可以实时的浏览数据,当文件变化时将会打印到屏幕上。
tee - 从 Stdin 读取数据,并同时输出到 Stdout 和文件
为了和我们的管道隐喻保持一致,Linux 提供了一个叫做 tee 的命令,这个命令制造了 一个”tee”,安装到我们的管道上。tee 程序从标准输入读入数据,并且同时复制数据 到标准输出(允许数据继续随着管道线流动)和一个或多个文件。当在某个中间处理 阶段来捕捉一个管道线的内容时,这很有帮助。这里,我们重复执行一个先前的例子, 这次包含 tee 命令,在 grep 过滤管道线的内容之前,来捕捉整个目录列表到文件 ls.txt:1
2
3
4
5 先通过grep过滤掉一部分,然后同时输出到ls.txt 和屏幕上
ls /usr/bin | grep zip | tee ls.txt
bunzip2
bzip2
....
总结归纳
一如既往,查看这章学到的每一个命令的文档。我们已经知道了他们最基本的用法。 它们还有很多有趣的选项。随着我们 Linux 经验的积累,我们会了解命令行重定向特性 在解决特殊问题时非常有用处。有许多命令利用标准输入和输出,而几乎所有的命令行 程序都使用标准错误来显示它们的详细信息。